


A diagnostic perception in healthcare. A personality’s dialogue in an interactive sport. An autonomous decision from a customer support agent. Every of those AI-powered interactions is constructed on the identical unit of intelligence: a token.
Scaling these AI interactions requires companies to contemplate whether or not they can afford extra tokens. The reply lies in higher tokenomics — which at its core is about driving down the price of every token. This downward development is unfolding throughout industries. Current MIT analysis discovered that infrastructure and algorithmic efficiencies are decreasing inference prices for frontier-level efficiency by as much as 10x yearly.
To know how infrastructure effectivity improves tokenomics, take into account the analogy of a high-speed printing press. If the press produces 10x output with incremental funding in ink, vitality and the machine itself, the fee to print every particular person web page drops. In the identical means, investments in AI infrastructure can result in far larger token output in contrast with the rise in price — inflicting a significant discount in the fee per token.
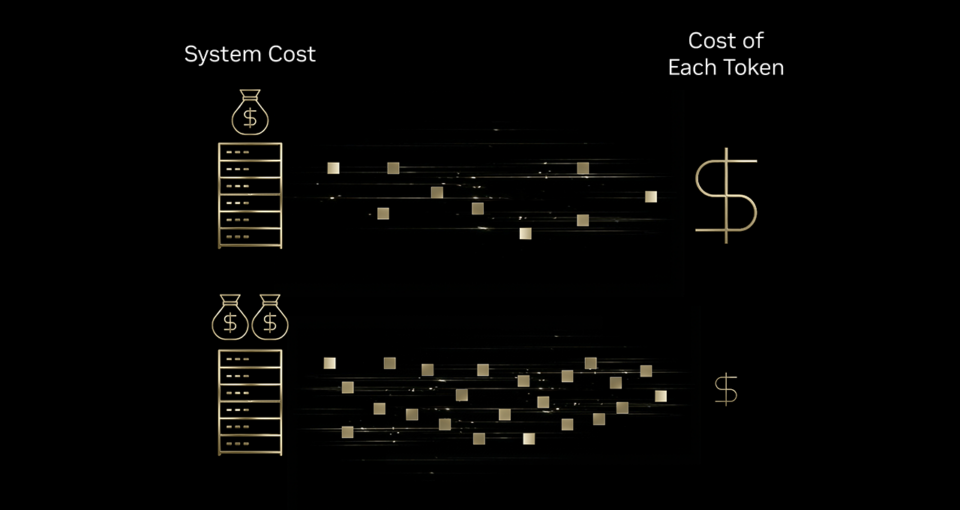
That’s why main inference suppliers together with Baseten, DeepInfra, Fireworks AI and Collectively AI are utilizing the NVIDIA Blackwell platform, which helps them scale back price per token by as much as 10x in contrast with the NVIDIA Hopper platform.
These suppliers host superior open supply fashions, which have now reached frontier-level intelligence. By combining open supply frontier intelligence, the intense hardware-software codesign of NVIDIA Blackwell and their very own optimized inference stacks, these suppliers are enabling dramatic token price reductions for companies throughout each trade.
Healthcare — Baseten and Sully.ai Reduce AI Inference Prices by 10x
In healthcare, tedious, time-consuming duties like medical coding, documentation and managing insurance coverage types minimize into the time medical doctors can spend with sufferers.
Sully.ai helps clear up this downside by growing “AI workers” that may deal with routine duties like medical coding and note-taking. As the corporate’s platform scaled, its proprietary, closed supply fashions created three bottlenecks: unpredictable latency in real-time medical workflows, inference prices that scaled sooner than income and inadequate management over mannequin high quality and updates.
To beat these bottlenecks, Sully.ai makes use of Baseten’s Mannequin API, which deploys open supply fashions equivalent to gpt-oss-120b on NVIDIA Blackwell GPUs. Baseten used the low-precision NVFP4 knowledge format, the NVIDIA TensorRT-LLM library and the NVIDIA Dynamo inference framework to ship optimized inference. The corporate selected NVIDIA Blackwell to run its Mannequin API after seeing as much as 2.5x higher throughput per greenback in contrast with the NVIDIA Hopper platform.
Consequently, Sully.ai’s inference prices dropped by 90%, representing a 10x discount in contrast with the prior closed supply implementation, whereas response occasions improved by 65% for important workflows like producing medical notes. The corporate has now returned over 30 million minutes to physicians, time beforehand misplaced to knowledge entry and different handbook duties.
Gaming — DeepInfra and Latitude Scale back Price per Token by 4x
Latitude is constructing the way forward for AI-native gaming with its AI Dungeon adventure-story sport and upcoming AI-powered role-playing gaming platform, Voyage, the place gamers can create or play worlds with the liberty to decide on any motion and make their very own story.
The corporate’s platform makes use of giant language fashions to answer gamers’ actions — however this comes with scaling challenges, as each participant motion triggers an inference request. Prices scale with engagement, and response occasions should keep quick sufficient to maintain the expertise seamless.

Latitude runs giant open supply fashions on DeepInfra’s inference platform, powered by NVIDIA Blackwell GPUs and TensorRT-LLM. For a large-scale mixture-of-experts (MoE) mannequin, DeepInfra decreased the fee per million tokens from 20 cents on the NVIDIA Hopper platform to 10 cents on Blackwell. Transferring to Blackwell’s native low-precision NVFP4 format additional minimize that price to simply 5 cents — for a complete 4x enchancment in price per token — whereas sustaining the accuracy that clients anticipate.
Operating these large-scale MoE fashions on DeepInfra’s Blackwell-powered platform permits Latitude to ship quick, dependable responses cheaply. DeepInfra inference platform delivers this efficiency whereas reliably dealing with site visitors spikes, letting Latitude deploy extra succesful fashions with out compromising participant expertise.
Agentic Chat — Fireworks AI and Sentient Basis Decrease AI Prices by as much as 50%
Sentient Labs is targeted on bringing AI builders collectively to construct highly effective reasoning AI programs which are all open supply. The objective is to speed up AI towards fixing more durable reasoning issues by analysis in safe autonomy, agentic structure and continuous studying.
Its first app, Sentient Chat, orchestrates advanced multi-agent workflows and integrates greater than a dozen specialised AI brokers from the group. Because of this, Sentient Chat has large compute calls for as a result of a single person question may set off a cascade of autonomous interactions that sometimes result in pricey infrastructure overhead.
To handle this scale and complexity, Sentient makes use of Fireworks AI’s inference platform operating on NVIDIA Blackwell. With Fireworks’ Blackwell-optimized inference stack, Sentient achieved 25-50% higher price effectivity in contrast with its earlier Hopper-based deployment.
This increased throughput per GPU allowed the corporate to serve considerably extra concurrent customers for a similar price. The platform’s scalability supported a viral launch of 1.8 million waitlisted customers in 24 hours and processed 5.6 million queries in a single week whereas delivering constant low latency.
Buyer Service — Collectively AI and Decagon Drive Down Price by 6x
Customer support calls with voice AI usually finish in frustration as a result of even a slight delay can lead customers to speak over the agent, hold up or lose belief.
Decagon builds AI brokers for enterprise buyer assist, with AI-powered voice being its most demanding channel. Decagon wanted infrastructure that might ship sub-second responses beneath unpredictable site visitors hundreds with tokenomics that supported 24/7 voice deployments.

Collectively AI runs manufacturing inference for Decagon’s multimodel voice stack on NVIDIA Blackwell GPUs. The businesses collaborated on a number of key optimizations: speculative decoding that trains smaller fashions to generate sooner responses whereas a bigger mannequin verifies accuracy within the background, caching repeated dialog parts to hurry up responses and constructing computerized scaling that handles site visitors surges with out degrading efficiency.
Decagon noticed response occasions beneath 400 milliseconds even when processing hundreds of tokens per question. Price per question, which is the full price to finish one voice interplay, dropped by 6x in contrast with utilizing closed supply proprietary fashions. This was achieved by the mixture of Decagon’s multimodel method (some open supply, some educated in home on NVIDIA GPUs), NVIDIA Blackwell’s excessive codesign and Collectively’s optimized inference stack.
Optimizing Tokenomics With Excessive Codesign
The dramatic price financial savings seen throughout healthcare, gaming and customer support are pushed by the effectivity of NVIDIA Blackwell. The NVIDIA GB200 NVL72 system additional scales this influence by delivering a breakthrough 10x discount in price per token for reasoning MoE fashions in contrast with NVIDIA Hopper.
NVIDIA’s excessive codesign throughout each layer of the stack — spanning compute, networking and software program — and its associate ecosystem are unlocking large reductions in price per token at scale.
This momentum continues with the NVIDIA Rubin platform — integrating six new chips right into a single AI supercomputer to ship 10x efficiency and 10x decrease token price over Blackwell.
Discover NVIDIA’s full-stack inference platform to be taught extra about the way it delivers higher tokenomics for AI inference.
Source link
#Main #Inference #Suppliers #Reduce #Prices #10x #Open #Supply #Fashions #NVIDIA #Blackwell
